챗봇 구축 시 ChatGPT 활용의 한계와 장점


AI 학습용 데이터와 챗봇 구축 사업을 전문으로 하다 보니 종종 위와 같은 질문을 받게 됩니다. 결론부터 말하자면 ‘아직은 한계점이 분명하나 결국 시간문제다’라고 할 수 있을 것 같습니다. 좀 더 자세히 살펴볼까요?
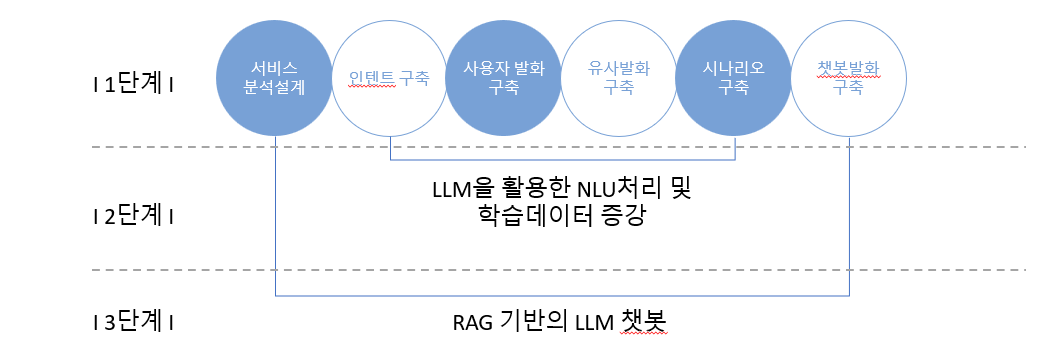
챗봇은 기본적으로 사용자 의도 분석이 핵심이라 사용자 발화를 사전에 정의된 인텐트에 얼마나 정확하게 매칭하느냐가 관건입니다. 이를 위해 크게 3단계의 과정이 필요합니다.
- 다루고자 하는 인텐트(사용자 의도) 체계를 구축하고 각각의 인텐트를 대표할 만한 챗봇 발화문(답변)을 구축합니다.
- 챗봇 이용 과정에서 들어오는 사용자 발화문(명령/질문)들을 구조화하고 각 발화별로 사용자가 할법한 다양한 유사 발화문을 추가로 구축합니다.
- 질문 1개 당 통상 20개 이상의 유사 발화문을 구축하게 됩니다.
- 사용자 발화문(질문)과 인텐트를 매칭하고 특정 업무를 수행하도록 연결합니다.
그동안 챗봇 시장은 인텐 트와 사용자 발화문을 정확히 매칭하기 위한 NLU 기술 구현에 많은 노력을 기울여왔습니다. 덕분에 챗봇 프레임워크별(빌더별) 성능 차이는 크지 않고, 일반적인 업무 수행에는 대체로 무리가 없는 수준입니다. 물론 그럼에도 사용자 눈높이에 맞는 성능 구현을 위해서는 아직도 많은 비용과 자원의 투입이 필요합니다.
ChatGPT의 활용은 투입 자원을 획기적으로 줄이고, 더 높은 성능의 챗봇을 구현할 수 있을 것이란 기대에서 출발합니다. 하지만 실제로 이를 적용해 보면 아직은 실무에 적용하기 어려운 점들도 있는데, 대표적으로 아래의 내용이 알려진 한계입니다.
ChatGPT의 한계: 챗봇에 활용하기 어려운 이유
- 환각(Hallucination, 할루시네이션)
시장에서는 ChatGPT의 환각 이슈를 줄이기 위해 여러 시도를 하고 있지만 이는 어디까지나 ‘줄이기’ 위한 노력일 뿐 완전히 사라지는 것을 의미하는 것은 아닙니다.(물론 TEXTNET도 환각 이슈를 최소화하기 위한 여러 프롬프트 엔지니어링 방법론을 활용하고 있습니다.) 일상 대화가 목적이라면 어느 정도의 환각 이슈는 용인될 수 있겠지만, 목적형 챗봇(Task-oriented)의 경우 100가지 답변 중 하나만 틀려도 큰 이슈가 될 수 있으니 치명적인 약점인 셈입니다. - 데이터 보안
OpenAI의 이용 약관에 따르면 ChatGPT에 보내는 모든 내용은 학습 데이터로 활용될 수 있습니다. 데이터 보안이 중요한 기업 입장에선 넘기 힘든 허들임에 분명합니다. 물론 OpenAI는 ‘API를 통해 입력된 데이터는 모델 학습에 활용하지 않는다’고 주장하지만, 이를 곧이곧대로 믿을 기업은 거의 없습니다. 현재로서는 아래의 방법으로 데이터 보안 이슈를 일부 해소할 수 있습니다.- Azure OpenAI Service를 활용
- ChatGPT의 Optout(옵트아웃) 기능을 활용
위 2가지 한계점은 ChatGPT 활용의 최대 걸림돌입니다. 데이터 보안 이슈는 현시점에서 어느 정도 해결이 가능하다고 보지만 환각 이슈는 사실 LLM의 태생적인 한계라 해결이 쉽지 않습니다. 물론 그렇다고 ChatGPT의 가능성을 무시하기엔 너무나 우수한 성능을 가지고 있는 것도 사실입니다.
ChatGPT의 언어 이해 능력과 챗봇 NLU 비교
그럼 거짓말을 하지 못하도록 ChatGPT의 입을 봉인하는 건 어떨까요? ChatGPT를 NLU(사용자 발화 이해) 영역으로만 한정하여 사용하는 겁니다. 앞서 언급한 대로 효과적인 챗봇 운영을 위해서는 챗봇에게 사용자의 발화를 정확히 이해시키는 것이 매우 중요합니다. 이를 위해 사용자 대표 발화문과 유사 발화문 구축에 많은 자원을 쏟게 되는데, 문제는 사용자의 발화가 예상을 벗어나는 경우가 많다는 것입니다. ChatGPT를 활용함으로써 비교적 적은 자원으로 사용자의 다양한 발화를 커버할 수 있습니다. 이를 좀 더 구체적으로 나열해보면 아래와 같습니다.
- 사용자 발화 이해 능력의 극대화
- ChatGPT를 활용함으로써 사용자 발화를 이해하는 능력(NLU)의 획기적인 개선이 가능
- 기존의 유사 발화문 구축 과정을 자동화할 수 있고(*이는 NLG의 영역이기도 함)
- 고객의 예상치 못한 발화(엣지 케이스)에도 적절한 대응이 가능하며
- 이를 통해 기존의 유사 발화문 구축과 인텐트 설계에 소요되는 비용과 자원을 상당 부분 줄일 수 있음
- ChatGPT를 활용함으로써 사용자 발화를 이해하는 능력(NLU)의 획기적인 개선이 가능
- 복합 요청(인텐트)의 이해와 수행
- ChatGPT의 폭넓은 언어 이해를 기반으로 챗봇의 슬롯필링(Slot-filling) 단계를 단순화하고 더 복잡한 요청 처리가 가능
- 기존의 단계별 Slot-value 매칭(또는 시나리오 구축)과정에서 벗어나 2개 이상의 동질 또는 이질적인 인텐트를 이해하고 필요한 과정을 한꺼번에, 혹은 순차적으로 해결할 수 있습니다.
- ChatGPT의 폭넓은 언어 이해를 기반으로 챗봇의 슬롯필링(Slot-filling) 단계를 단순화하고 더 복잡한 요청 처리가 가능
그럼 NLU 관점에서 ChatGPT는 챗봇 NLU 시스템보다 늘 경쟁우위에 있는 걸까요?
ChatGPT vs 챗봇 NLU: 무엇을 선택해야 할까?
챗봇 프레임워크 내에서 NLU는 사용자 발화를 사전 정의된 의도에 할당하는 ’예측적’ 성격을 띱니다. 반면에 LLM은 생성 모델이라 인텐트 매칭에 필요한 충분한 성능이 담보되어 있지 않습니다. 또한 결과의 일관성 측면에서도 챗봇 NLU가 아직은 우위에 있습니다(ChatGPT는 동일한 질문에도 다른 답변을 하거나, 답을 하지 않아야 하는 질문에 답을 하는 경우가 종종 있습니다.)
물론 프롬프트를 활용해서 인텐트와 챗봇 발화문을 사전 학습하는 것만으로도 할루시네이션을 줄이고 정확한 답변을 전달하는데 도움이 될 수 있습니다. 하지만 이 역시도 토큰 수 제한으로 모든 정보를 프롬프트에 넣을 수 없다는 한계가 존재합니다. 또한 LLM은 기본적으로 확률에 기초한 모델이라 고도로 정교화된 프롬프트가 아니라면, 복잡할수록 원하는 결괏값이 나오지 않을 가능성이 높아집니다.
ChatGPT 활용의 비용 효율성과 대중화 가능성
그럼에도 불구하고, 사람들은 ChatGPT를 챗봇에 활용하고 싶어 합니다. 그 어떤 모델보다 뛰어난 성능으로 우리의 일상에 빠르고 강력하게 스며든 모델임에는 틀림없기 때문입니다. 진정한 의미의 기술 대중화를 이룬 첫 사례로 평가받는 만큼, 이제 기술을 모르는 기업이라도 ChatGPT를 서비스에 활용하고 싶어 하는 것은 당연한 시대 흐름일 것입니다.
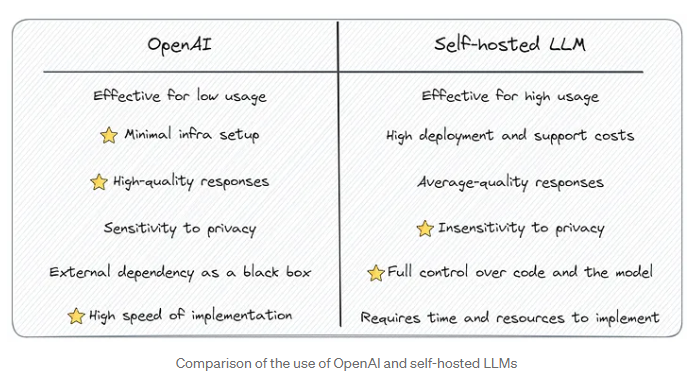
일부 기업들은 자체 LLM을 구축하려는 움직임이 늘고 있으나, 일반 기업들 입장에선 ChatGPT의 효율성을 무시할 수 없습니다.
- 하루 10,000명 이하의 활성 사용자라면 자체 LLM보다 Open API를 사용하는 것이 비용 면에서 최적의 선택입니다.
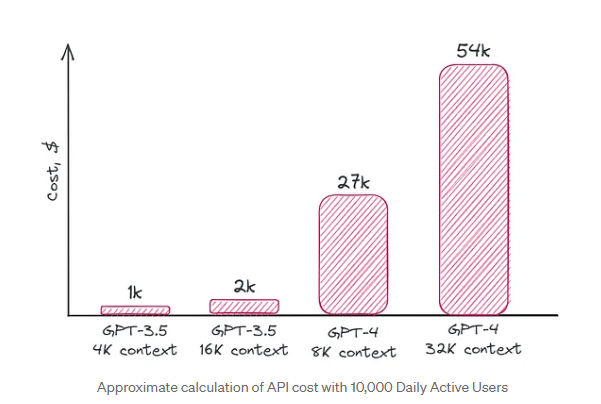
- 오픈소스 모델을 활용한다면 GPT-3.5나 GTP-4보다 낮은 성능에 만족해야 합니다. 소규모 LM을 만들어본다고 한들 GPT-3.5 수준의 성능을 구현하려면 결국 큰 버전의 모델이 필요합니다. 자체 모델을 만든다면 서버 비용, DevOps 전문가, ML 엔지니어 비용 추가도 고려해야 합니다.
재원 마련에 부담이 없고 데이터 자산이 풍부한 대기업은 여전히 자체 LLM 구축을 선호할 것입니다. 하지만 예산과 자원의 압박이 있는 대다수 기업들에게 필요한 건 무엇일까요? 우리에겐 적당한 가격과 적당한 성능의 대중적인 AI 서비스(모델)가 분명 필요합니다.
Reference
- Cobus Greyling, 2023. 02. 08, Large Language Models (LLMs) Will Not Replace Traditional Chatbot NLU…For Now, Medium
- Sergei Savvov, 2023. 08. 11. You don’t need hosted LLMs, do you?, Medium
고객의 입장에서 기술을 바라봅니다.
TEXTNET 소개
지금의 딥러닝을 있게 한 AI Guru 제프리 힌튼의 데이터셋 'ImageNet'에 어원을 둔 TEXTNET은 (주)스피링크가 운영하는 AI/챗봇을 위한 텍스트 데이터 설계 및 구축 서비스입니다.
TEXTNET은 언어학, 심리학, 전산언어학 석·박사를 포함한 전문 인력으로 구성된 언어전문가 그룹으로서, 고객사의 니즈에 부합하는 텍스트 데이터를 설계·가공·구축하고 내부 R&D를 통해 설계 방식을 지속적으로 개선하여 최적의 데이터 설계 방법을 제안합니다. 프로젝트 목적에 따라 적합한 숙련 작업자를 선별하여 투입하고, 체계적이고 효율적으로 고품질의 학습데이터를 생산합니다.
TEXTNET은 삼성, LG, KT, SK 등 유수 대기업의 데이터 구축 파트너로 함께하며 금융, 마케팅, 콘텐츠, 메타버스, 서비스 기획, CS 등 다양한 도메인을 다루고 있습니다.