LLM 평가 지표: 최선의 LLM 성능 평가 방법은 무엇일까?


기존 시나리오 기반의 챗봇이 LLM 챗봇으로 대체되면서, 이제 챗봇은 사용자의 질문을 이해하고 더 자연스러운 답변을 생성해 내기 시작했습니다. 답변의 자율성이 확대됨에 따라 할루시네이션, AI 윤리 등의 문제가 대두되고 있으며 이를 보완하면서도 더욱 사람처럼 답변하는 LLM을 만들기 위한 연구들이 계속 진행되고 있습니다. 더불어 LLM을 평가하는 평가 지표에 대한 연구도 활발하게 이루어지고 있습니다.
이 글에서는 기존 평가 지표에는 어떤 것들이 있으며, LLM을 제대로 평가하기 위해서는 어떤 평가 지표를 따라야 하는지 살펴보고자 합니다.
잘 알려진 LLM 성능 평가 방법
LLM 평가 방법으로는 크게 세 가지로 수식을 활용한 방법, 인간이 직접 평가하는 방법, 벤치마크 데이터셋을 활용한 방법이 있습니다.
수식을 활용하는 방법
수식을 활용한 방법으로는 대표적으로 아래의 방법들이 있습니다.
- PPL(Perplexity): 각 토큰 예측에 고려되는 분기계수를 측정하는 방법
- BLEU(Bilingual Evaluation Understudy): N-gram을 기반으로 인간이 생성한 문장과 일치하는 정도를 측정하는 방법
- METEOR(Metric for Evaluation of Translation with Explicit ORdering): BLEU 방법에서 recall까지 고려하여 말뭉치 수준에서 상관관계까지 측정하는 방법
- ROUGE(Recall-Oriented Understudy for Gisting Evaluation): 주로 문서 요약(text summarization)의 품질을 평가하는 데 사용되는 방법으로, n-gram을 기반으로 하는 ROUGE-N과 가장 긴 공통부분 열(Longest Common Subsequence) 기반으로 하는 ROUGE-L 등이 있음
해당 평가 방법의 장단점은 아래와 같습니다.
장점
- 비용 절감
- 객관적인 성능 평가 가능
단점
- 실제 사용자 만족도 측정 불가
- 성능 개선 방향성 제시 불가
이 방법은 LLM의 자연어 생성 능력에 대한 평가 방법입니다. 그렇기 때문에 해당 LLM의 우수함을 평가할 수는 있지만, 실제 사용자가 사용하기 적합한지에 대한 평가로 보기에는 어렵습니다.
인간이 직접 평가하는 방법
LLM이 생성한 답변을 인간이 직접 평가하는 방법(Human Evaluation)은 챗봇 평가 지표를 개발하여 각 지표에 대한 점수를 매기는 방법입니다. 대표적으로는 구글 어시스턴트에서 발표한 대화 기술 평가 지표인 SSA(Sensibleness and Specificity Average) 등이 있습니다.
해당 평가 방법의 장단점은 아래와 같습니다.
장점
- 실제 사용자 만족도 측정 가능
- 성능 개선 방향성 제시 가능
단점
- 높은 비용
- 평가 일관성 유지 어려움
챗봇을 사용하는 것은 결국 인간이므로, 인간이 느끼기에 어떠한지는 아주 중요한 평가 지표입니다. 그래서 인간이 직접 평가하는 방법은 서비스가 배포되기 전 최종 평가 수단으로 활용, 실제 사용자의 만족도를 예측해 볼 수 있다는 장점이 있습니다. 또한 인간이 직접 평가를 진행하며 느낀 의견 전달이 가능하기 때문에 개선 방향성을 확인할 수 있다는 장점도 있습니다.
하지만 이러한 방법은 높은 비용이 들며 평가자 별 주관이 다르기 때문에 일관성 유지가 어렵습니다. 따라서 어떤 평가 지표를 어떤 기준에 따라 어떤 점수로 평가할지에 대한 기획과 설계가 굉장히 중요합니다.
벤치마크 데이터셋으로 평가하는 방법
미리 구축한 벤치마크 데이터셋에 대하여 LLM이 답변한 내용을 점수로 매겨 평가하는 방식입니다. 평가하려는 분야에 따라 여러 태스크로 나뉘어져 있으며 GLUE, SQuAD, Evals 등 여러 LLM leaderboard가 존재합니다.
LLM 성능 평가 태스크
- 추론 능력(ARC): 초등학교 수준의 과학 질문지로만 구성되어 질문에 대한 답변이 얼마나 적절한지 측정하는 지표
- 상식 능력(HellaSwag): 인간에게는 사소하지만 AI가 답변하기는 어려운 짧은 글 및 지시 사항에 알맞은 문장을 생성하는지 여부를 측정하는 지표
- 언어 이해력(MMLU): 57개의 다양한 과목(과학, 기술, 공학 등)에 대하여 답변이 얼마나 정확한지를 측정하는 지표
- 환각 방지 능력(TruthfulQA): 인간이 잘못 인지 혹은 거짓으로 답변할 수 있는 질문에 대해 AI가 얼마나 진실하게 답변하는지를 측정하는 지표
- 한국어 생성 능력: 역사 왜곡, 환각 오류, 형태소 부착 오류, 불규칙 활용 오류, 혐오 표현 등에 대한 광범위한 유형을 포함한 질문에 AI가 한국어 일반 상식에 부합하는 답변을 하는지 측정하는 지표
이외에도 Winogrande, COPA, MultiRC, LAMBADA, WiC, WSC, CoT dataset, DROP, GSM-8K 등 다양한 태스크와 벤치마크 데이터셋이 존재합니다.
보통 공개되어 있는 벤치마크 데이터셋을 통한 LLM 평가는 leaderboard를 통해 이루어지며, 모델의 점수 및 순위를 매겨볼 수 있습니다. 이러한 벤치마크 데이터셋 리더보드 평가의 장단점은 아래와 같습니다.
장점
- 비용 절감
- 객관적인 평가 결과 도출
- 타 모델과 성능 비교 가능
단점
- 평가 결과에 대한 이유 확인 불가
- 평가 일관성 유지 어려움
- 모델에 따른 평가 지표 부적합 문제
기존 구축된 데이터셋을 통한 평가이기 때문에 비용 부담이 적으며, 보편적인 모델에 대한 평가를 위해 구축되었기에 객관적인 평가가 가능합니다. 또한 타 모델과의 성능 비교가 가능합니다.
하지만 보통 벤치마크 데이터셋은 공개되지 않기 때문에 모델의 평가 결과에 대한 이유를 확인할 수 없으며, 운영처에서 벤치마크 데이터셋의 내용을 변경하게 될 경우 점수가 달라질 수 있습니다. 또한 모델의 목적이나 특성을 고려하지 않기 때문에 모델에 따라 부적합한 평가 지표일 수 있습니다.
그렇기 때문에 일회성 평가가 아닌 버전 업데이트에도 대응이 가능한 지속적인 평가를 위해서는 공개 벤치마크 데이터셋을 활용하기보다 해당 챗봇에 맞춤화된 벤치마크 데이터셋을 구축하여 활용하는 것이 좋습니다.
LLM 목적에 맞는 평가 지표
위에서 다양한 평가 지표를 살펴보았지만, 사실 LLM은 표준화 된 평가 지표가 존재하지 않습니다. 그렇기에 특정 평가 지표에서 SOTA(State-of-the-art)를 달성했다 하더라도 가장 좋은 모델이라고 칭하기는 어렵습니다.
2023년 12월 구글에서는 자사의 새로운 인공지능 모델 ‘제미나이’가 MMLU 평가 90.04%로 OpenAI의 ‘GPT-4’의 86.4%보다 앞섰다고 발표했습니다. 하지만 일각에서는 해당 사실이 과장된 내용일 수 있다며, 평가를 ‘제미나이’에 더 유리한 방식으로 진행한 것으로 보인다는 의견도 있었습니다.
그렇다면 언어 모델은 어떤 지표로 어떻게 평가되어야 할까요? 이를 알아보기 위해서는 평가하려는 언어 모델이 적용되는 분야 및 필요한 기능을 먼저 생각해 보아야 합니다.
목적에 따른 LLM 평가 지표가 필요한 이유
예를 들면 아래와 같은 챗봇은 각각 다른 목적을 가집니다.

위에서 살펴본 것과 같이 LLM은 각 목적에 따라 “사용자의 불편함에 구체적인 해결 방법을 제시하는”, “사용자의 니즈를 찾아 도움을 주는 기능 또는 정보를 제공하는”, “사용자에게 흥미를 주는” 등의 목표를 달성하기 위해 기준으로 삼을 평가 지표를 구성해야 합니다. 그 이유는 아래와 같습니다.
위에서 살펴본 것과 같이 LLM은 각 목적에 따라 “사용자의 불편함에 구체적인 해결 방법을 제시하는”, “사용자의 니즈를 찾아 도움을 주는 기능 또는 정보를 제공하는”, “사용자에게 흥미를 주는” 등의 목표를 달성하기 위해 기준으로 삼을 평가 지표를 구성해야 합니다. 그 이유는 아래와 같습니다.
- LLM의 목적에 따라 평가에 사용되는 지표가 달라지기 때문에
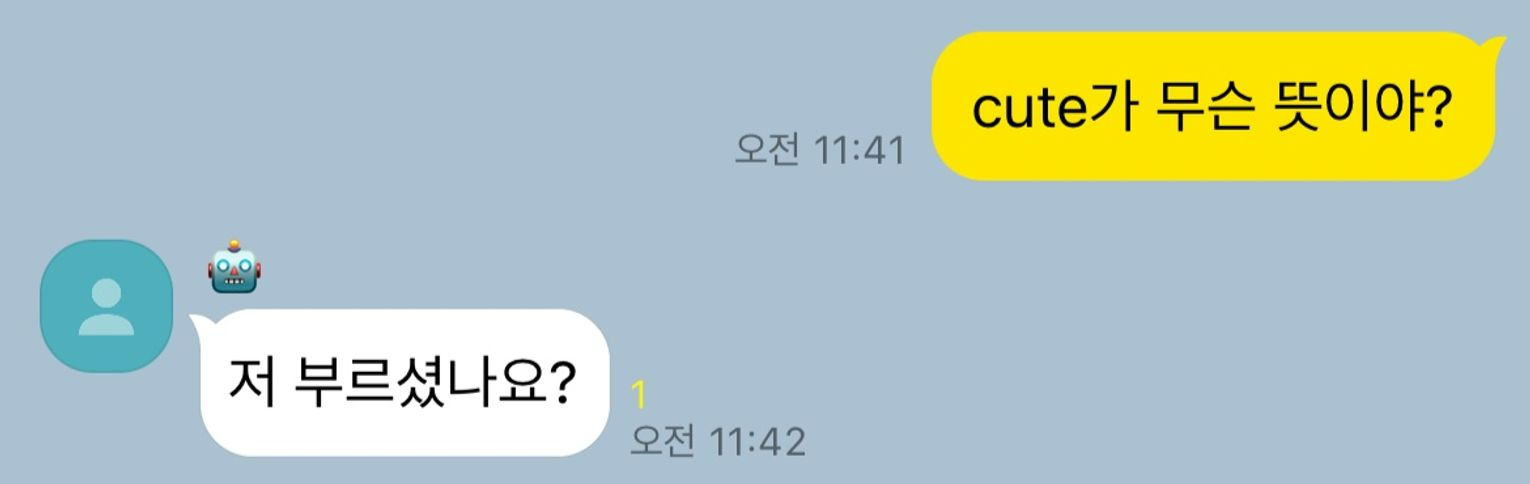
예를 들어, 위와 같이 ‘감성 대화’가 목적인 LLM은 사용자와 친근하게 대화하며 심리적 안정 및 재미를 제공하는 것이 목적입니다. 이러한 모델을 추론 능력(ARC) 기준으로 평가한다면 낮은 점수를 기록할 수밖에 없습니다.
해당 LLM의 매력을 가장 잘 드러내기 위해서는 ‘사용자에게 정확한 정보를 전달하는가?’보다는 ‘사용자가 말하는 내용에 대하여 매력적으로 답변하는가?’를 기준으로 해당 내용을 평가할 수 있는 지표를 세워야 합니다.
- LLM의 목적에 따라 같은 평가 지표더라도 세부 기준이 달라지기 때문에
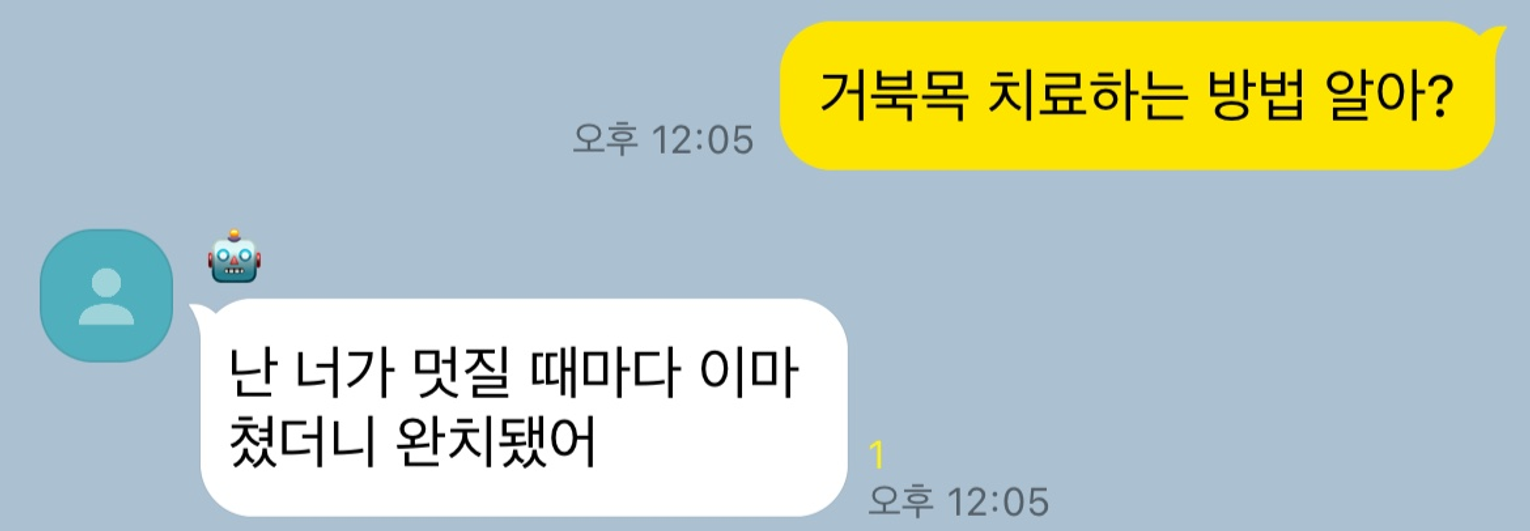

위 대화에서 ‘만족도’를 평가한다고 해봅시다. 사용자에게 정보를 전달하는 AI 에이전트라면 사용자가 원하는 정보를 제공하지 못하였기에 낮은 점수를 받을 것입니다. 하지만, 감성대화봇이었다면 사용자에게 재미를 전달하였기 때문에 높은 점수를 받을 수 있을 것입니다.
- LLM의 목적에 따라 평가 기준의 난도를 조정해야 하기 때문에
고등학생의 과학 학습을 돕는 챗봇을 만든 경우라면, 초등학생 수준의 과학 질문지로 구성된 기존의 추론 능력(ARC) 벤치마크 데이터셋으로 평가하는 것은 무의미합니다. 더 높은 수준인 고등학생 수준의 과학 질문지로 구성된 추론 능력(ARC) 벤치마크 데이터셋을 구성하여 평가하는 것이 맞습니다. 하지만 무조건 높은 수준을 기준으로 잡아서도 안 됩니다.

수학을 예시로 들자면, 위 내용처럼 학년별로 교과서에서 다루는 내용이 다릅니다. 그 이유는 사람의 생각하는 방식의 차이를 고려하기 때문입니다. 이러한 차이를 무시하고 초등학생 학습용 챗봇에 고등 수학까지 학습시킨다면, 실제 사용자인 초등학생의 만족도는 떨어질 수밖에 없습니다.
초등학생에게는 중고등학생과는 달리 경험을 토대로 연산을 설명합니다. 예를 들면 “사과 7개가 있는데, 3개를 먹는다면 4개가 남게 됩니다.”과 같은 내용입니다. 이런 내용으로 음수를 설명하기는 어렵기 때문에 논리적인 사고를 할 수 있는 중학생이 되기 전까지는 ‘작은 수에서 큰 수를 뺄 수 없다’라고 학습하게 됩니다. 이를 고려하지 않고, 초등학생 학습용 챗봇이 음수를 설명하게 된다면 사용자인 초등학생은 뺄셈에 대한 이해도가 떨어지게 되고 결국 사용 만족도가 낮아질 것입니다.
이 외에도 대상 LLM에 대한 이해(페르소나, 도메인, 사용자 등)를 토대로 평가 지표를 구성할 수 있습니다.
- 사용자의 발화를 제대로 이해하여 답변하는지
- 윤리적 문제 없이 안전하게 답변하는지
- 맞춤법을 잘 지키는지
- 생성한 문장이 자연스럽고 매끄럽게 읽히는지
이러한 평가 지표는 구체적이고 집요하게 설계해야 합니다. 그 이유는 평가 일관성 때문입니다. 아래에서는 평가 일관성이 왜 필요하고, 평가 일관성을 유지하기 위한 방법에는 어떤 것들이 있는지 살펴보겠습니다.
평가 일관성을 유지하기 위한 방법
비슷한 발화에 대하여 작업 초반과 후반에 평가한 결과가 달라지기도 하고, 그날 기분이나 환경에 따라 일관성이 무너지기도 합니다.

위 내용에 대하여 어느 날에는 답변이 적절하다고 느껴질 수도 있고, 어떤 날에는 답변이 너무 성의 없게 느껴질 수도 있습니다. 또한, 작업자별로 주관적인 생각이 다르기 때문에 누가 평가하는지에 따라 결과가 달라질 수 있습니다.
이에 맞추어 모든 데이터를 전수 검사하기에는 시간이 너무 많이 소요되고, 그냥 두기에는 일관성 유지가 되지 않겠죠. 그렇기 때문에 ‘평가 일관성’을 유지하기 위해서는 초반의 기획과 설계 작업이 굉장히 중요합니다. 그 외의 평가 일관성이 필요한 이유는 아래와 같습니다.
평가 일관성이 필요한 이유
- 평가 점수에 대한 신뢰도를 위해
- 객관적인 결과를 위해
- 비용 절감을 위해
데이터를 공급받는 입장이라고 가정해 봅시다. 평가 데이터를 검토하던 중 같은 데이터에 대하여 평가 결과가 다르다면 전체 평가 데이터에 대한 신뢰도가 떨어지겠죠? 한 번 그런 데이터를 발견한다면 제대로 평가한 데이터에 대해서도 의구심이 들기 시작할 것입니다. 이처럼 평가 일관성은 평가 점수의 신뢰도와 직결됩니다.
또한, 사람이 하기 때문에 주관적일 수밖에 없다는 이유로 평가 일관성이 무너진다면 평가를 진행하는 의미가 없어집니다. 그렇기 때문에 주관적인 항목에서도 최대한 객관적인 세부 지표를 세워 평가 일관성을 유지해야 합니다. 예를 들어, 모델 업데이트 전후 비교를 위해 평가를 진행하였는데, 모델의 업데이트 전과 후에 평가 일관성이 무너져 객관적인 결과가 나오지 않는다면 비용과 시간만 쓴 셈입니다.
따라서 LLM 평가를 진행하기 위해서는 작업 전, 중, 후에 충분한 고민과 협의가 필요합니다. 샘플 평가를 통해 현재 지표가 평가하고자 하는 바가 명확하게 평가되는지 확인하거나, 해당 지표에 대하여 평가 가이드라인에서 놓치는 바가 없는지 등을 살펴야 합니다. 작업자별로 편차가 발생하는 부분은 각자 해당 평가를 진행한 이유와 근거를 통해 가장 적절하고 보편적인 판단 기준을 채택합니다. 이를 통해 언제, 누가, 어떻게 평가를 진행하더라도 일관성 있는 평가 결과를 도출할 수 있습니다. 또한 크로스체크, 실시간 이슈 공유 등을 통해 평가 결과에 대한 타당한 근거를 제시할 수 있어야 합니다.
추가로 LLM의 특성에 따라 문제점을 발굴하고 개선안을 제시하기도 합니다. 이러한 작업이 필요한 이유는 아래에서 확인할 수 있습니다.
LLM 평가가 성능 평가에서 끝나면 안 되는 이유: 문제점 탐색 및 개선안 제시
LLM에 맞는 평가 지표를 세우고 이를 일관성 있게 평가함으로써 모델의 성능을 가늠할 수 있습니다. 이러한 평가를 진행하다 보면 해당 LLM에 대한 인사이트를 얻기도 합니다.
LLM 평가를 진행하며 얻을 수 있는 인사이트
- 모델의 고질적인 문제 답변 패턴
- 문제에 대한 구체적인 개선 방안
- 바람직한 추가 업데이트 방향
- 전반적인 LLM 답변에 대한 의견
LLM 평가 작업을 통해 사용자 발화에 대한 문제 답변 패턴을 인식할 수 있습니다. 자주 발생하는 문제 또는 어색한 문체에 대하여 사용자 입장의 개선 방안을 떠올리기도 하고, 사용자 요청에서 자주 등장하지만 현재 제공하지 않는 기능에 대해 정리할 수도 있습니다. 이 외에도 LLM 답변에 대한 사용성 측면의 의견, 장단점 등의 인사이트를 발굴할 수 있습니다. 이 내용들은 평가를 위해 대화 로그를 경험하며 축적할 수 있는 인사이트로 LLM 평가를 진행하며 같이 생각하고 고민해 보기 좋은 내용입니다.
이 글에서는 LLM의 성능을 정량적인 수치로 다루기 위해서는 해당 LLM에 적합한 평가 지표를 연구하고 개발하여 일관성 있게 평가되어야 한다는 내용을 다루었습니다. 또한 LLM을 평가하며 얻을 수 있는 인사이트까지 살펴보았습니다. LLM 평가와 관련하여 이어질 AI의 ‘인간다움’ 평가, AI 윤리 문제 등의 주제에도 많은 관심 부탁드립니다.
유의미한 데이터를 창출하기 위해 배우고 성장 중인 통계학도입니다.
TEXTNET 소개
지금의 딥러닝을 있게 한 AI Guru 제프리 힌튼의 데이터셋 'ImageNet'에 어원을 둔 TEXTNET은 (주)스피링크가 운영하는 AI/챗봇을 위한 텍스트 데이터 설계 및 구축 서비스입니다.
TEXTNET은 언어학, 심리학, 전산언어학 석·박사를 포함한 전문 인력으로 구성된 언어전문가 그룹으로서, 고객사의 니즈에 부합하는 텍스트 데이터를 설계·가공·구축하고 내부 R&D를 통해 설계 방식을 지속적으로 개선하여 최적의 데이터 설계 방법을 제안합니다. 프로젝트 목적에 따라 적합한 숙련 작업자를 선별하여 투입하고, 체계적이고 효율적으로 고품질의 학습데이터를 생산합니다.
TEXTNET은 삼성, LG, KT, SK 등 유수 대기업의 데이터 구축 파트너로 함께하며 금융, 마케팅, 콘텐츠, 메타버스, 서비스 기획, CS 등 다양한 도메인을 다루고 있습니다.